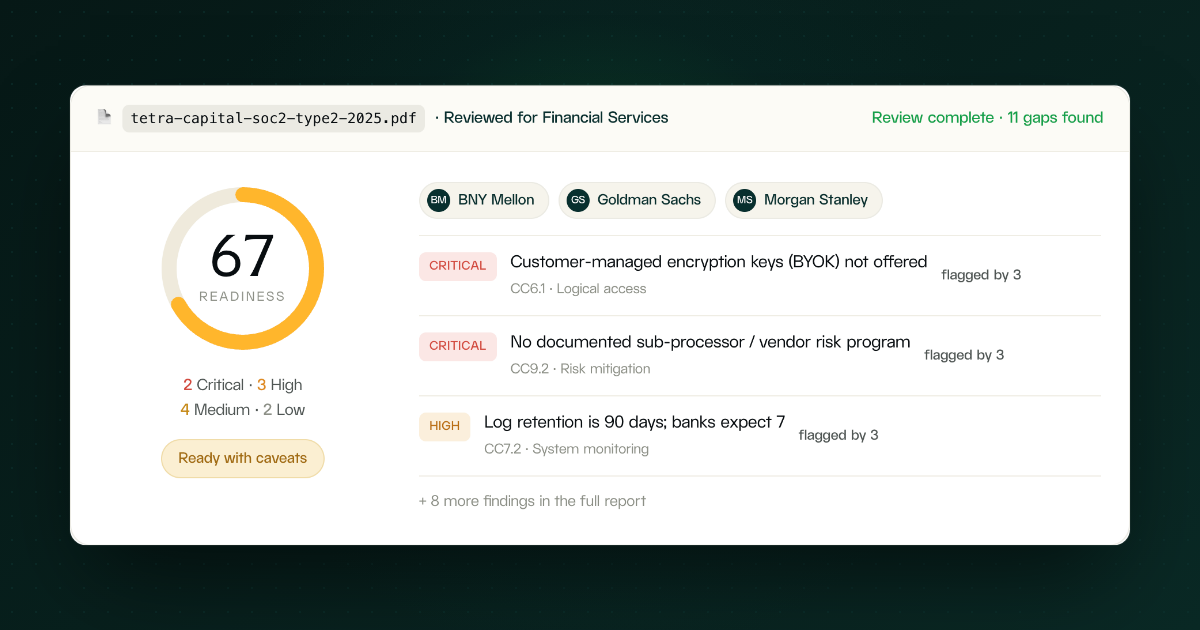
New: Pressure test your SOC 2 report against buyer requirements
Free check

Learn how to prioritize security vulnerabilities without a dedicated security team. A practical framework for cutting through the noise and fixing what actually matters.
It's Monday morning. You open Slack to find 47 new alerts, all labeled "Critical." GitHub Dependabot has flagged twelve dependency vulnerabilities. AWS Inspector surfaced two thousand container vulnerabilities from your latest container build and Guard Duty is alerting you to eight different infrastructure findings.
You pour your coffee and stare at the screen. The question that's become a permanent resident in your head: Which of these security vulnerabilities actually matter?
This article walks through a practical approach to vulnerability prioritization for lean teams: how to cut through the noise, focus on what matters, and build a process that doesn't consume your week.
The natural instinct is to sort by severity and start at the top. Every vulnerability scanner encourages this by throwing CVSS scores at you like confetti at a parade. CVSS (Common Vulnerability Scoring System) assigns a number from 0 to 10 based on how severe a vulnerability could be. Higher is worse. Simple, right?
Here's the problem: CVSS measures theoretical severity, not actual risk to your specific environment.
Consider two vulnerabilities in your codebase:
Vulnerability A has a CVSS score of 9.8. It exists in a development dependency that only runs during your build process. It never touches production. An attacker would need access to your CI/CD pipeline to exploit it.
Vulnerability B has a CVSS score of 6.5. It's in your authentication flow. It's internet-facing. There's a proof-of-concept exploit circulating on GitHub.
Which one should you fix first?
If you're sorting by CVSS score alone, you'd fix Vulnerability A first. That's probably the wrong call.
CVSS tells you what could happen under ideal conditions for an attacker. It doesn't account for whether those conditions exist in your environment. It doesn't know if the vulnerable component is even reachable. It doesn't factor in whether anyone is actually exploiting this vulnerability in the wild.
Think of CVSS as one input to your prioritization decision, not the answer itself. To make better decisions, you need more context. But before you can layer on that context, you need to solve a more fundamental problem: knowing what you're actually dealing with.
Before you can prioritize vulnerabilities effectively, you need to know what you're actually dealing with. If you're running Dependabot, Snyk, AWS Inspector, and a container scanner, you could have the same CVE showing up four times across four dashboards. That's not four problems. It's one problem with four notifications.
This consolidation step is where many startups lose hours every week. You're copying CVE IDs into spreadsheets, cross-referencing across tools, trying to figure out which alerts are duplicates and which are genuinely new. It's tedious, error-prone, and it doesn't actually make your systems more secure. And that's if you're even bothering to do it at all. After a few rounds of this, most people just stop due to fatigue.
Some teams build internal scripts to aggregate findings. Others designate someone to manually reconcile reports. Neither approach scales well.
This is one of the core problems Fencer solves: pulling vulnerability findings from your code, cloud infrastructure, containers, and dependencies into a single view, automatically deduplicated. Instead of starting your week by consolidating four dashboards, you start with one prioritized list of actual issues. The consolidation is already done.
But whether you use Fencer to get a unified view of vulnerabilities, or build your own aggregation process, the principle is the same: you can't prioritize what you can't see clearly. Get to a single source of truth first. Once you have that unified view, you can apply a real prioritization framework.
Once you have a unified view of your security findings, you’ll need a framework that's both rigorous and fast. Evaluate each vulnerability against four factors: exploitability, exposure, impact, and fix complexity.
The most important question isn't "how bad could this be?" but "is anyone actually doing this?"
Check the CISA Known Exploited Vulnerabilities (KEV) catalog. If a vulnerability appears there, it means attackers are actively exploiting it in the real world. That moves it to the front of your queue, regardless of CVSS score.
EPSS (Exploit Prediction Scoring System) is another useful tool. It estimates the probability that a vulnerability will be exploited in the next 30 days based on real-world data. A CVSS 7.0 with a 90% EPSS score is a bigger deal than a CVSS 9.5 with a 0.1% EPSS score.
AI tools have made it trivially easy to go from proof-of-concept to working attack. A quick search for "CVE-XXXX exploit" can also tell you a lot. If there's a working proof-of-concept on GitHub, you have less time than you think.
Knowing a vulnerability is exploitable isn't enough. You also need to know whether an attacker can actually reach the vulnerable component in your environment.
Not all code is created equal from a security perspective. A vulnerability in an internet-facing API endpoint is fundamentally different from the same vulnerability in an internal admin tool that requires VPN access.
Ask yourself:
A critical vulnerability in a test database that's not connected to anything important is lower priority than a medium vulnerability in your payment processing service.
Once you know something is exploitable and reachable, the next question is: what happens if it's exploited?
Prioritize based on what you care about protecting. For most startups, that hierarchy looks something like: customer data, authentication systems, payment processing, then everything else. Your specific order might differ based on your business.
Finally, consider the cost of the fix itself. Two vulnerabilities with equal risk profiles might have very different remediation costs. One might be a simple dependency update. Another might require refactoring a core component.
This doesn't mean you should always fix the easy things first. But when you're choosing between two similar-priority issues, the one you can resolve in 30 minutes probably gets done before the one that requires a two-week project.
Also consider: can you mitigate this without fully fixing it? Sometimes adding a WAF rule or tightening network access buys you time to address the root cause properly.
With these four factors in mind, you have what you need to make informed prioritization decisions. The next step is applying this framework efficiently.
Having a framework is great. Applying it efficiently is what makes the difference. Here's a practical process that turns the framework above into a repeatable weekly habit.
If you've already consolidated your findings into a single view (see above), you're ahead. If not, start by identifying unique CVEs across your tools. Don't count the same vulnerability multiple times just because multiple scanners found it.
Set aside anything that only exists in development or test environments. These matter eventually, but they're not your Monday morning emergency. Focus your triage time on what's actually deployed and serving customers.
For each production vulnerability, do a quick exploitability check. Is it in the CISA KEV catalog? What's the EPSS score? Does a quick search show active exploitation? Flag anything with known exploitation for immediate attention.
Sort what remains by where it lives in your architecture. Authentication and identity come first. Payment processing and financial data second. Customer PII third. Internal tooling last.
Look for opportunities to fix multiple issues at once. Updating one dependency might resolve several CVEs. A single infrastructure change might address multiple findings. Batching saves context-switching time and reduces deployment overhead.
A dedicated 30-minute triage session once a week is more effective than reacting to alerts as they come in. It forces you to see patterns, reduces context-switching, and gives you a clear queue to work from.
Of course, even with a good process, you'll end up with more vulnerabilities than you can fix immediately. That's not a failure. It's reality. The question is how you handle the gap.
You're not going to fix everything. That's fine. What matters is being intentional about what you're deferring and why. This is called risk acceptance. Here’s how to approach this:
At some point, though, even a good manual process hits its limits. When you're spending more time on process than on fixes, it's time to consider whether tooling can help.
Manual triage works when you have a manageable number of findings. It starts to break down when you're facing hundreds of vulnerabilities across multiple systems, or when half your security time goes to consolidation and deduplication rather than actually fixing things.
If you're spending more time managing your security tools than fixing security issues, that's a signal that your tooling isn't working for you.
Good security tooling for startups should:
Fencer does all of this. Findings from code, cloud, containers, and dependencies flow into one place, already deduplicated and prioritized based on your actual infrastructure. When something surfaces, you see not just what's wrong, but why it matters in your environment and what to do about it. One-click fixes handle many common issues, so you spend your time on the problems that actually require engineering judgment.
"Repetitive findings and false positives are really costly for a startup. Fencer is much more focused on findings that actually matter, which helps us stay secure without slowing the team down."
— Ben Papillon, CTO & Co-founder, Schematic
Vulnerability prioritization isn't about achieving the impossible goal of zero vulnerabilities. It's about making informed decisions about risk with the resources you have.
Want to stop spending half your security time on consolidation? See how Fencer brings all your vulnerability findings into one prioritized view. Learn more about Fencer Vulnerability Management →
Weekly triage works well for most teams. It's frequent enough to catch new issues before they become emergencies, but not so frequent that you're constantly context-switching. Block 30 minutes on your calendar, review new findings, update your priorities, and move on. You'll spend less total time than you would reacting to alerts throughout the week.