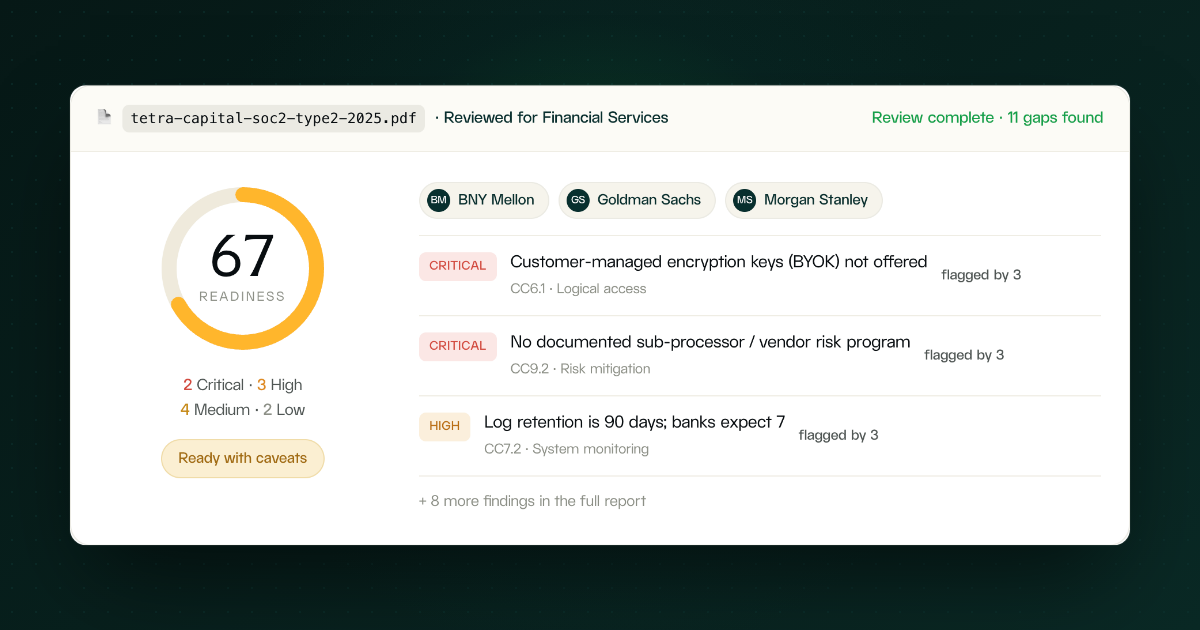
New: Pressure test your SOC 2 report against buyer requirements
Free check
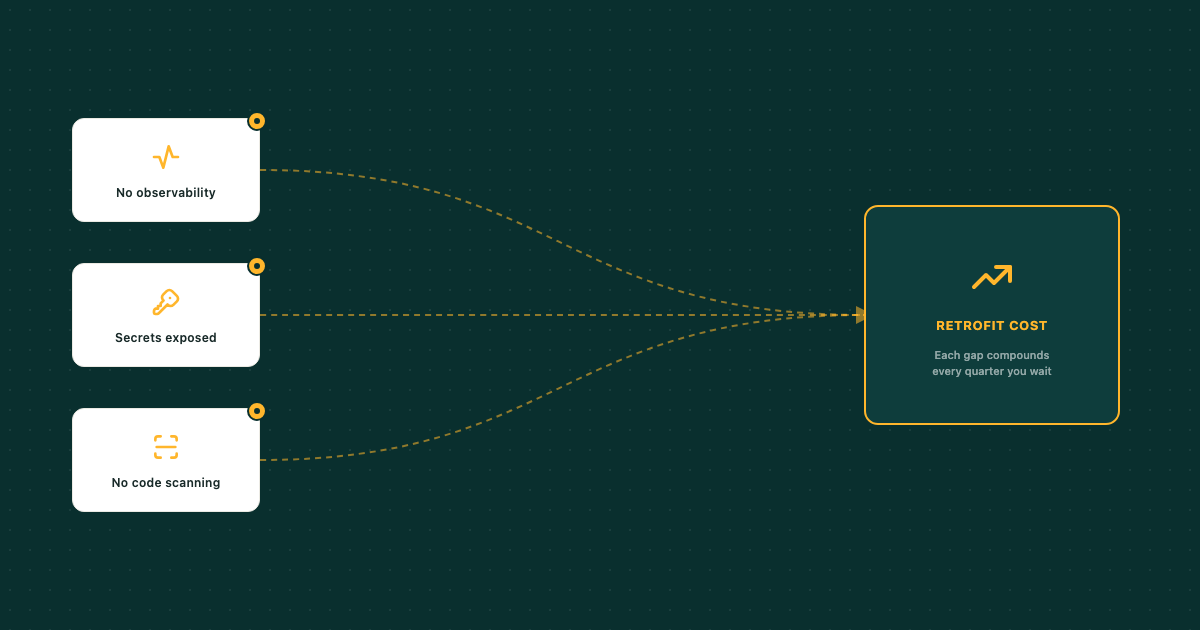
Secrets in the wrong places, no infrastructure observability, no code scanning. The early gaps that cost the most to retrofit — and what to get right from the start.
By Tim Olshansky, Co-Founder, Fencer
The earliest startup security gaps are cheap to close and expensive to ignore. The same fix that takes an afternoon at five engineers becomes a multi-week project once you have real users, a full team, and a production system you can't take offline. Solving them early is the easy version of a problem that only gets harder with every quarter you wait.
I've seen the same pattern at every company I've been part of: teams move fast, leave a few things loose, and plan to clean it up later. That holds for most technical debt, but security debt behaves differently. By the time you get to it, you're changing a running production system and the habits a whole team has built around the current setup, which is what makes a late fix so much harder than an early one.
A few gaps show up again and again. Here are the three worth getting right from the start.
When I was CTO at a B2B SaaS company growing into enterprise deals, we were paying for New Relic. It was doing its job: application performance, application logs. What it wasn't doing: anything related to infrastructure activity, database logs, or change tracking. We had no visibility into what was happening at the infrastructure level, no record of who had made what changes, and no detection rules running against anything.
What we also didn't have was the time to babysit a logging platform and write detection rules for every scenario we should be watching for. That's not a reasonable expectation of an engineering team that's also shipping product. And the tools that could do it well — Splunk, primarily, with Sumo Logic as the only real alternative at the time — were too expensive to run ourselves and too time-intensive to configure without someone who did it full-time.
What we did instead: we hired a managed service provider that had already bought a Splunk license. They connected everything, applied their detection rules to our logs, and sent us a report every week or two — here's the activity we flagged, here's what we think you should look at. That gave me more confidence in our detection posture than anything we could have built in-house at that stage.
The gap at this stage is structural: you're running application logs only, with nothing watching the infrastructure and no detection running against any of it. It's manageable to close when you're small, because the surface area is limited and you can outsource the expertise without it costing much. It becomes a real project at fifty people, with a large cloud footprint and two years of log volume to deal with.
This one is still a problem in 2026, and it's been a problem at every company I've been close to.
The most common version: secrets live in source code, or in infrastructure provider settings in a way that technically works but isn't using the actual secrets tooling those providers offer. Both mistakes are easy to make and genuinely difficult to reverse once they're established — not impossible, but difficult in the way that requires re-architecting how your application manages its settings, convincing engineers to change habits that have been working fine from their perspective, and doing all of it without breaking a production system.
The right approach is simple, which is what makes the delay so common: small teams look at the problem and think, we're not a target yet, we'll tighten this up when we're bigger. By the time they're bigger, the cost is significantly higher. At thirty people it's already hard. At five it's an afternoon.
For a long time at that same company, we had nothing running against the codebase to find security issues. No scanner, no static analysis, nothing that would surface a problem at the point it was being introduced.
Setting up code scanning — SonarCloud, for example, was what we used — takes close to no time. Once it's running on every pull request, the ongoing effort is minimal. It catches things before they make it to production, and it catches them at the point where they're cheapest to fix: before a release, before deployment, before a customer is running the affected version.
The "brush your teeth for two minutes a day" version of this genuinely applies. Teams skip it not because it's hard, but because nothing has gone wrong yet.
These aren't independent problems. Secrets in the wrong place go undetected in part because there are no detection rules watching for exposure. A code vulnerability slips through because scanning wasn't running when it was introduced. Missing observability means that when something does go wrong, you're working backward from an incident rather than catching it while it's happening.
Getting each one right at the start doesn't take long. Getting all three right takes longer than getting one, but far less than retrofitting any of them on a live system with a full team and production risk at every step.
The other thing that's consistently true: the sophistication of these tools can grow with the company. You don't need enterprise-grade infrastructure at five engineers — you need something watching your logs. You don't need a full secrets management program — you need secrets not to be in your source code. The bar at the start is genuinely low. The cost of not clearing it gets higher every quarter.
If you're working through which of these to address first, the Startup Security Field Guide covers exactly that — what to prioritize early and in what order.